本博客分享的其他视频下载地址:《传智播客Hadoop实战视频下载地址[共14集]》、《传智播客Hadoop课程视频资料[共七天]》、《Hadoop入门视频分享[共44集]》、《Hadoop大数据零基础实战培训教程下载》、《Hadoop2.x 深入浅出企业级应用实战视频下载》、《Hadoop新手入门视频百度网盘下载[全十集]》 本博客收集到的Hadoop学习书籍分 w397090770 11年前 (2013-12-02) 87926℃ 59评论297喜欢
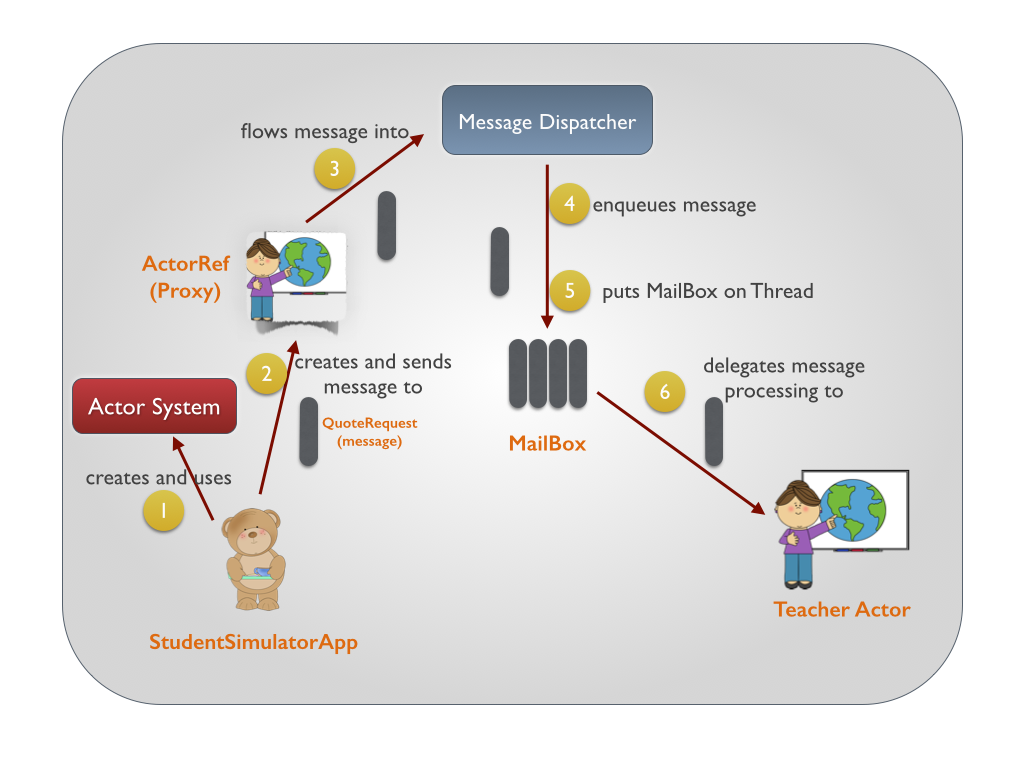
Akka学习笔记系列文章:《Akka学习笔记:ACTORS介绍》《Akka学习笔记:Actor消息传递(1)》《Akka学习笔记:Actor消息传递(2)》 《Akka学习笔记:日志》《Akka学习笔记:测试Actors》《Akka学习笔记:Actor消息处理-请求和响应(1) 》《Akka学习笔记:Actor消息处理-请求和响应(2) 》《Akka学习笔记:ActorSystem(配置)》《Akka学习笔记 w397090770 10年前 (2014-10-13) 21959℃ 5评论40喜欢
一. 问答题1.hive如何调优?2.hive如何权限控制?3.hbase写数据的原理是什么?4.hive能像关系数据库那样,建多个库吗?5.hbase宕机如何处理?6.hive实现统计的查询语句是什么?7.生产环境中为什么建议使用外部表?8.hadoop mapreduce创建类DataWritable的作用是什么?9.为什么创建类DataWritable?二. 思考题1.假 w397090770 8年前 (2016-08-26) 3519℃ 0评论5喜欢
本文原文:Apache Spark as a Compiler: Joining a Billion Rows per Second on a Laptop Deep dive into the new Tungsten execution engine:https://databricks.com/blog/2016/05/23/apache-spark-as-a-compiler-joining-a-billion-rows-per-second-on-a-laptop.html本文已经投稿自:http://geek.csdn.net/news/detail/77005 《Spark 2.0技术预览:更容易、更快速、更智能》文中简单地介绍了Spark 2.0相关 w397090770 8年前 (2016-05-27) 6003℃ 1评论16喜欢
《Spark meetup(Beijing)资料分享》 《Spark meetup(杭州)PPT资料分享》 《北京第二次Spark meetup会议资料分享》 《北京第三次Spark meetup会议资料分享》 第三次北京Spark Meetup活动将于2014年10月26日星期日的下午1:30到6:00在海淀区中关村科学院南路2号融科资讯中心A座8层举行,本次分享的主题主要是MLlib与分布式机器学 w397090770 10年前 (2014-10-09) 4463℃ 6评论6喜欢
全新美国区 Apple ID 注册教程参见:2021年最新美区 Apple ID 注册教程使用苹果手机的有可能知道,国内使用的 App Store 只能下载国内的一些 APP 应用。有一些 APP 并没有在国内 App Store 上架,这时候就无法下载。我们需要使用一个国外的 Apple ID 账号,但是很多人手上一般都是只有国内的账号,这篇文章就来教大家如何把一个中国区的 w397090770 3年前 (2021-10-10) 1473℃ 0评论2喜欢
本系列文章将展示ElasticSearch中23种非常有用的查询使用方法。由于篇幅原因,本系列文章分为六篇,本文是此系列的第三篇文章。欢迎关注大数据技术博客微信公共账号:iteblog_hadoop。《23种非常有用的ElasticSearch查询例子(1)》《23种非常有用的ElasticSearch查询例子(2)》《23种非常有用的ElasticSearch查询例子(3)》《23种非常有用 w397090770 8年前 (2016-08-17) 3685℃ 0评论3喜欢
我已经在之前的 《一条 SQL 在 Apache Spark 之旅(上)》、《一条 SQL 在 Apache Spark 之旅(中)》 以及 《一条 SQL 在 Apache Spark 之旅(下)》 这三篇文章中介绍了 SQL 从用户提交到最后执行都经历了哪些过程,感兴趣的同学可以去这三篇文章看看。这篇文章中我们主要来介绍 SQL 查询计划(Query Plan)常见的处理模型(processing model)。数 w397090770 4年前 (2020-05-13) 1704℃ 0评论6喜欢
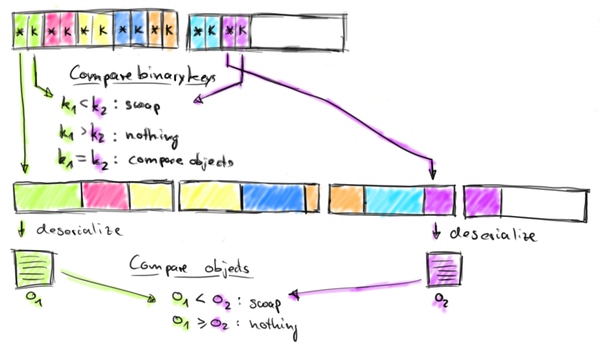
我们在 《Presto 中支持的七种 Join 类型》 这篇文章中介绍了 Presto 可用的 JOIN 操作的基础知识,以及如何在 SQL 查询中使用它们。有了这些知识,我们现在可以了解 Presto 的内部结构以及它如何在内部执行 JOIN 操作。本文将介绍 Presto 如何执行 JOIN 操作以及用于 JOIN 的算法。JOIN 的实现几乎所有的数据库引擎一次只 JOIN 两个表。即 w397090770 3年前 (2021-11-17) 786℃ 0评论0喜欢
本书作者:Hanish Bansal、Saurabh Chauhan、Shrey Mehrotra,由Packt出版社于2016年4月出版,全书共486页。通过本书将学习到以下的知识:(1)、Learn different features and offering on the latest Hive(2)、Understand the working and structure of the Hive internals(3)、Get an insight on the latest development in Hive framework(4)、Grasp the concepts of Hive Data Model(5)、M zz~~ 7年前 (2017-05-26) 6366℃ 0评论22喜欢
Spark Summit 2017 Europe 于2017-10-24 至 26在柏林进行,本次会议议题超过了70多个,会议的全部日程请参见:https://spark-summit.org/eu-2017/schedule/。本次议题主要包括:开发、研究、机器学习、流计算等领域。从这次会议可以看出,当前 Spark 发展两大方向:深度学习(Deep Learning)提升流系统的性能( Streaming Performance)如果想及时了解Spar w397090770 7年前 (2017-11-02) 3538℃ 0评论13喜欢
下面IP由于地区不同可能无法访问,请多试几个。 国内高匿代理 IP PORT 匿名度 类型 位置 响应速度 最后验证时间 117.176.56.224 8123 高匿名 HTTP w397090770 10年前 (2015-05-10) 21654℃ 0评论2喜欢
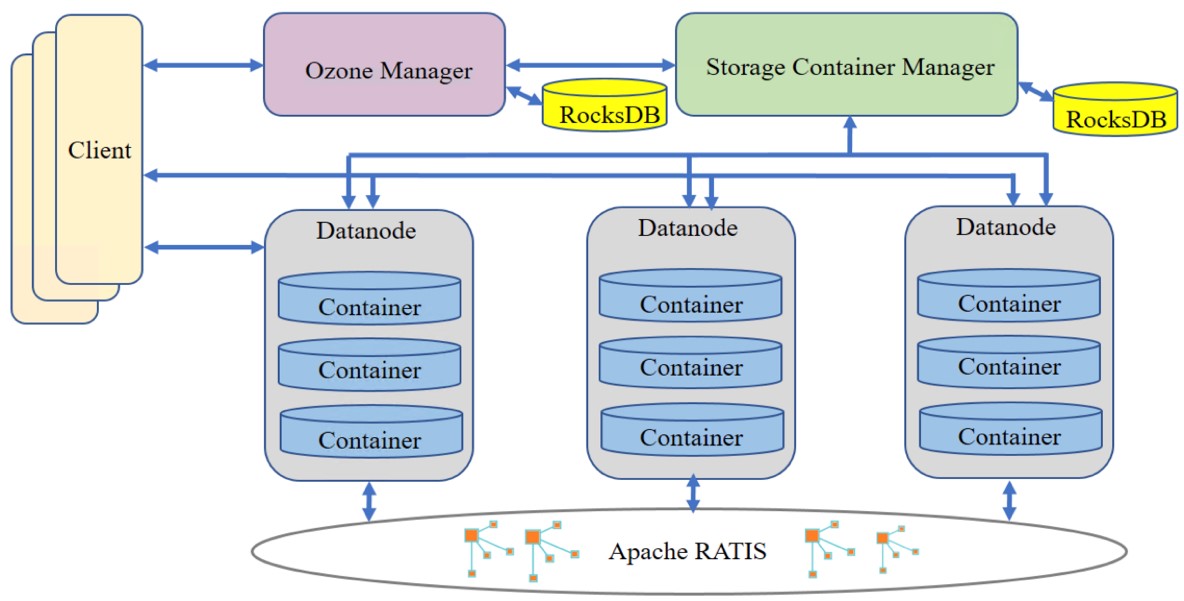
刚刚获悉,Apache基金董事会通过一致表决,正式批准分布式文件对象存储Ozone从Hadoop社区孵化成功,成为独立的Apache顶级开源项目。这意味着,作为腾讯大数据团队首个参与和主导的开源项目,Ozone已得到全球Apache技术专家的一致认可,成为世界顶级的存储开源项目之一。Ozone 是Apache Hadoop社区推出的面向大数据领域的新一代分布 w397090770 4年前 (2020-12-09) 1084℃ 0评论7喜欢
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoopApache Iceberg 是一种用于跟踪超大规模表的新格式,是专门为对象存储(如S3)而设计的。 本文将介绍为什么 Netflix 需要构建 Iceberg,Apache Iceberg 的高层次设计,并会介绍那些能够更好地解决查询性能问题的细节。如果想及时了解Spark、Hadoop或者HBase w397090770 5年前 (2020-02-23) 2975℃ 0评论6喜欢
bsie是使得IE6可以支持Bootstrap的补丁,Bootstrap是 twitter.com 推出的非常棒web UI工具库。目前,bsie使得IE6能支持bootstrap大部分特性,可惜,还有一些实在无法支持...下面的这个表格就是当前已经被支持的bootstrap的组件和特性:[code lang="bash"]组件 特性-----------------------------------------------------------grid fixed, fluidnavbar w397090770 9年前 (2015-12-26) 2317℃ 7评论3喜欢
本文资料来自2021年12月09日举办的 PrestoCon 2021,议题为《Presto at Tencent at Scale Usability Extension Stability Improvement》,分享者Junyi Huang 和 Pan Liu,均为腾讯软件工程师。Presto 已被腾讯采用为不同业务部门提供临时查询和交互式查询场景。在这次演讲中,作者将分享腾讯在生产中关于 Presto 的实践。关注 过往记忆大数据公众 w397090770 3年前 (2021-12-19) 724℃ 0评论0喜欢
我在《Hadoop&Spark解决二次排序问题(Hadoop篇)》文章中介绍了如何在Hadoop中实现二次排序问题,今天我将介绍如何在Spark中实现。问题描述二次排序就是key之间有序,而且每个Key对应的value也是有序的;也就是对MapReduce的输出(KEY, Value(v1,v2,v3,......,vn))中的Value(v1,v2,v3,......,vn)值进行排序(升序或者降序),使得Value(s1,s2,s3,......,sn),si w397090770 8年前 (2016-10-08) 6205℃ 0评论12喜欢
《Spark Streaming作业提交源码分析接收数据篇》、《Spark Streaming作业提交源码分析数据处理篇》 在昨天的文章中介绍了Spark Streaming作业提交的数据接收部分的源码(《Spark Streaming作业提交源码分析接收数据篇》),今天来介绍Spark Streaming中如何处理这些从外部接收到的数据。 在调用StreamingContext的start函数的时候, w397090770 10年前 (2015-04-29) 4398℃ 2评论9喜欢
如果我们需要通过编程的方式来获取到Kafka中某个Topic的所有分区、副本、每个分区的Leader(所在机器及其端口等信息),所有分区副本所在机器的信息和ISR机器的信息等(特别是在使用Kafka的Simple API来编写SimpleConsumer的情况)。这一切可以通过发送TopicMetadataRequest请求到Kafka Server中获取。代码片段如下所示:[code lang="scala"]de w397090770 8年前 (2016-05-09) 8251℃ 0评论4喜欢
我们都知道,使用Kafka Producer往Kafka的Broker发送消息的时候,Kafka会根据消息的key计算出这条消息应该发送到哪个分区。默认的分区计算类是HashPartitioner,其实现如下:[code lang="scala"]class HashPartitioner(props: VerifiableProperties = null) extends Partitioner { def partition(data: Any, numPartitions: Int): Int = { (data.hashCode % numPartitions) }}[/code] w397090770 9年前 (2016-03-29) 9207℃ 0评论9喜欢
新世纪以来,互联网及个人终端的普及,传统行业的信息化及物联网的发展等产业变化产生了大量的数据,远远超出了单台机器能够处理的范围,分布式存储与处理成为唯一的选项。从2005年开始,Hadoop从最初Nutch项目的一部分,逐步发展成为目前最流行的大数据处理平台。Hadoop生态圈的各个项目,围绕着大数据的存储,计算, w397090770 9年前 (2015-11-06) 7963℃ 0评论9喜欢
在 《HBase Rowkey 设计指南》 文章中,我们介绍了避免数据热点的三种比较常见方法:加盐 - Salting哈希 - Hashing反转 - Reversing其中在加盐(Salting)的方法里面是这么描述的:给 Rowkey 分配一个随机前缀以使得它和之前排序不同。但是在 Rowkey 前面加了随机前缀,那么我们怎么将这些数据读出来呢?我将分三篇文章来介绍如何 w397090770 6年前 (2019-02-24) 4661℃ 0评论11喜欢
本系列文章翻译自:《scala data analysis cookbook》第二章:Getting Started with Apache Spark DataFrames。原书是基于Spark 1.4.1编写的,我这里使用的是Spark 1.6.0,丢弃了一些已经标记为遗弃的函数。并且修正了其中的错误。 一、从csv文件创建DataFrame 如何做? 如何工作的 附录 二、操作DataFrame w397090770 9年前 (2016-01-16) 6559℃ 0评论16喜欢
最近在做给博客添加上传PDF的功能,但是在测试上传文件的过程中遇到了413 Request Entity Too Large错误。不过这个无错误是很好解决的,这个错误的出现是因为上传的文件大小超过了Nginx和PHP的配置,我们可以通过以下的方法来解决:一、设置PHP上传文件大小限制 PHP默认的文件上传大小是2M,我们可以通过修改php.ini里面的 w397090770 9年前 (2015-08-17) 20759℃ 0评论6喜欢
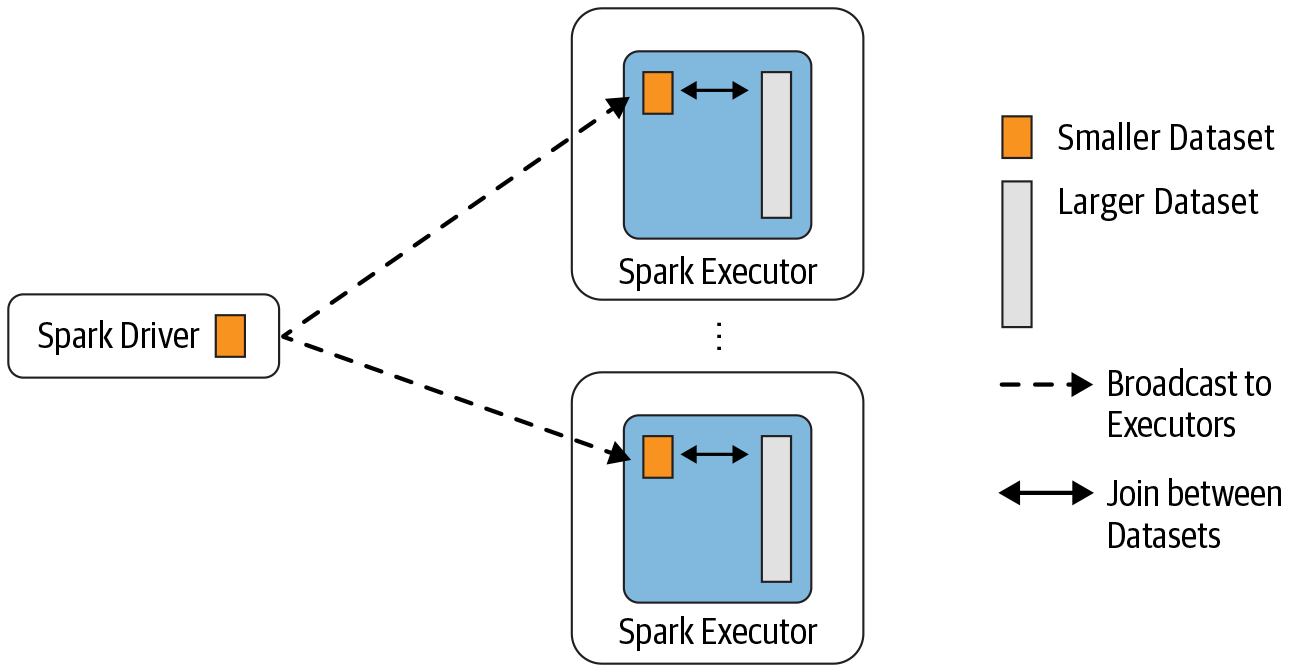
数据分析中将两个数据集进行 Join 操作是很常见的场景。在 Spark 的物理计划(physical plan)阶段,Spark 的 JoinSelection 类会根据 Join hints 策略、Join 表的大小、 Join 是等值 Join(equi-join) 还是不等值(non-equi-joins)以及参与 Join 的 key 是否可以排序等条件来选择最终的 Join 策略(join strategies),最后 Spark 会利用选择好的 Join 策略执行最 w397090770 4年前 (2020-09-13) 5071℃ 0评论13喜欢
Data + AI Summit 2022 于2022年06月27日至30日举行。本次会议是在旧金山进行,中国的小伙伴是可以在线收听的,一共为期四天,第一天是培训,后面几天才是正式会议。本次会议有超过200个议题,演讲嘉宾包括业界、研究和学术界的专家,本次会议主要分为六大块:数据分析, BI 以及可视化:了解最新的数据分析、BI 和可视化技术以及 w397090770 2年前 (2022-07-10) 607℃ 0评论3喜欢
在本博客的《Spark读取Hbase中的数据》文章中我谈到了如何用Spark和Hbase整合的过程以及代码的编写测试等。今天我们继续谈谈Spark如何和Flume-ng进行整合,也就是如何将Flune-ng里面的数据发送到Spark,利用Spark进行实时的分析计算。本文将通过Java和Scala版本的程序进行程序的测试。 Spark和Flume-ng的整合属于Spark的Streaming这块。在 w397090770 10年前 (2014-07-08) 23192℃ 4评论17喜欢
1、Hive内部表和外部表的区别? 1、在导入数据到外部表,数据并没有移动到自己的数据仓库目录下,也就是说外部表中的数据并不是由它自己来管理的!而表则不一样; 2、在删除表的时候,Hive将会把属于表的元数据和数据全部删掉;而删除外部表的时候,Hive仅仅删除外部表的元数据,数据是不会删除的! 那么, w397090770 8年前 (2016-08-26) 5654℃ 2评论20喜欢
在过去Spark社区创建了Spark 2.0的技术预览版,经过几天的投票,目前该技术预览版今天正式公布。《Spark 2.0技术预览:更容易、更快速、更智能》文章中详细介绍了Spark 2.0给我们带来的新功能,总体上Spark 2.0提升了下面三点: 1. 对标准的SQL支持,统一DataFrame和Dataset API。现在已经可以运行TPC-DS所有的99个查询,这99个查 w397090770 8年前 (2016-05-25) 2620℃ 0评论3喜欢
本文作者:李寅威,从事大数据、机器学习方面的工作,目前就职于CVTE联系方式:微信(coridc),邮箱(251469031@qq.com)原文链接: Spark2.1.0 + CarbonData1.0.0集群模式部署及使用入门1 引言 Apache CarbonData是一个面向大数据平台的基于索引的列式数据格式,由华为大数据团队贡献给Apache社区,目前最新版本是1.0.0版。介于 zz~~ 8年前 (2017-03-13) 3441℃ 0评论11喜欢






![[电子书]Apache Hive Cookbook PDF下载](https://www.iteblog.com/pic/Apache_Hive_Cookbook-iteblog.jpg)
![Spark Summit 2017 Europe全部PPT及视频下载[共69个]](https://www.iteblog.com/pic/spark/spark-summit-2017-europe-iteblog.png)